Sauvegarde complète (image disque) d'un serveur et stockage dans Azure Blob
Réaliser une sauvegarde ou un backup, ça vous dit quelque chose ? La réponse est probablement affirmative. Nous avons déjà tous ressenti le besoin de disposer d’une copie de nos données, qu’il s’agisse d’un simple fichier, d’une base de données ou d’un disque entier.
Aujourd’hui, nous allons nous attaquer à un type particulier de sauvegarde: les images disques. L’image d’un disque est la copie intégrale de ce dernier par blocs d’octets, indépendamment de la structure de son contenu en fichiers et en répertoires. Lorsque la destination d’une image disque est un fichier, on parle de fichier d’image disque. Ce dernier est très utilisé dans le cadre de la sauvegarde et de la restauration de données. Dans cet article, nous en créerons un à partir d’un serveur linux et nous le stockerons dans un conteneur de stockage Blob Azure.

Attachez vos ceintures, on va décoller !
Prérequis
Pour suivre ce tutoriel, vous aurez besoin de:
- un compte Azure
- un serveur linux
Moi je vais utiliser un petit serveur de Digital Ocean. Mais un serveur auprès de n’importe quel autre fournisseur cloud devrait faire l’affaire. Vous pouvez également utiliser un serveur on-premise ou même votre laptop. L’essentiel est que le système d’exploitation soit de type Unix/Linux et puisse exécuter la commande dd.
Stockage Blob Azure
Stockage Blob Azure (en anglais Azure Blob Storage) est une solution de stockage optimisée pour le cloud fourni par Microsoft dans Azure. Elle est destinée au stockage d’immenses quantités de données non structurées. On entend par données non structurées, des données qui n’obéissent pas à un modèle ou une définition de données en particulier. On peut en citer quelques-unes telles que les, images, audios, vidéos et documents. Le terme « Blob » est l’acronyme de Binary Large Object utilisé dans le secteur.
Le stockage Blob est utile dans de nombreux scénarios, mais l’un de ses emplois les plus répandus est le stockage de données pour la sauvegarde et la restauration.
Ressources du stockage Blob
Le stockage Blob est composé de trois types de ressources :
- Le compte de stockage
- Un conteneur dans le compte de stockage
- Un objet blob dans un conteneur
Le diagramme suivant montre la relation entre ces ressources:

Le compte de stockage organise un ensemble de blobs en conteneurs. Par analogie avec un disque classique, le compte de stockage correspond au système de fichiers, le conteneur à un dossier et le blob à un fichier.
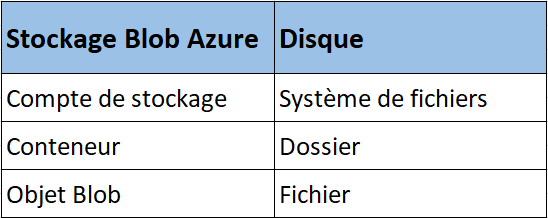
Les comptes de stockage peuvent avoir un nombre illimité de conteneurs, et ces derniers peuvent stocker un nombre illimité de blobs.
Création d’un compte de stockage
Commençons par créer notre compte de stockage en accédant au portail Azure. Dans la barre de recherche, on saisit storage account pour trouver le service.


Nous allons le nommer moncomptedestockage1 et garder tous les paramètres par défaut puis sélectionner review,et create. Vous devez choisir un nom unique.
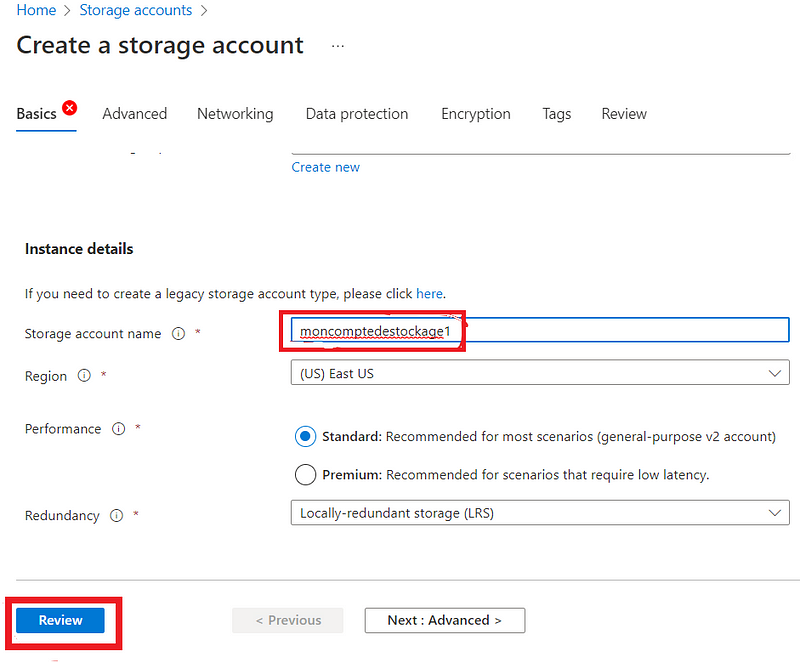
Après la création, on accède au nouveau compte de stockage puis on sélectionne _containers_afin de créer le conteneur.

Création d’un conteneur
Par défaut, un conteneur $logs est automatiquement créé par Azure.
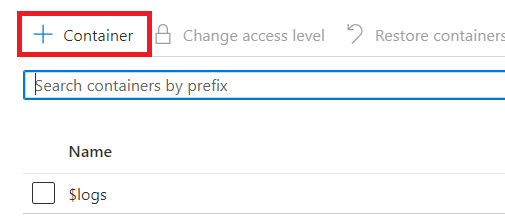
Nous allons nommer le nôtre, monconteneur. Une fois de plus, vous êtes libres de le nommer comme bon vous semble. Nous choisissons ensuite le niveau d’accès Private puis on clique sur le bouton Create situé au bas de la page.

Nous avons ainsi un deuxième conteneur dans la liste de nos conteneurs.
 liste des conteneurs
liste des conteneurs
Génération de signatures d’accès partagé (SAS)
Il existe plusieurs méthodes pour octroyer l’accès aux ressources du compte de stockage. Parmi elles, figurent les signatures d’accès partagé (SAP), en anglais shared access signature (SAS). Elles permettent d’accéder aux ressources du compte de stockage, mais elles vous offrent un contrôle plus précis sur cet accès. Vous pouvez contrôler les ressources auxquelles elles ont accès, les autorisations dont elles disposent sur ces ressources et la durée de leur accès à ces ressources.
Dans notre cas, nous allons accéder au conteneur monconteneur pour générer un jeton SAP avec les autorisations de lecture, écriture et de création.

Nous gardons, la durée de validité par défaut du jeton qui est de 8 heures. Vous pouvez l’étendre ou la restreindre selon votre besoin.

On clique ensuite sur le bouton Generate SAS token and URL

Le système génère un jeton SAP et une URL SAP.Veuillez noter ces deux valeurs, elles disparaitront à la fermeture de la page.
L’URL SAPest composée de l’URI de la ressource de stockage, suivie par un point d’interrogation, puis du jeton SAP. Exemple:

Création et transfert de l’image disque
Nous créerons une image disque brute au format “ .img” en utilisant l’utilitaire en ligne de commande dd. Puis nous allons compresser l’image avec gzip pour enfin la transférer vers notre conteneur Blob Azure grâce à azcopy .
Pour ce faire, connectons-nous au serveur qui contient le disque source à imager et procédons au :
Téléchargement de AZCopy
C’est quoi AZCopy ?
azcopy est un utilitaire en ligne de commande développé par Microsoft, qui nous permettra de transférer des fichiers depuis notre serveur vers notre compte de stockage Azure et inversement. A l’heure actuelle, la dernière version de azcopyest la version 10. azcopy est juste un fichier exécutable qui ne nécessite aucune installation avant usage. Il en existe une version propre à chaque système d’exploitation (OS). Dans le cadre de ce tutoriel, nous ne nous intéresserons qu’à la version pour Linux. Si vous souhaitez l’exécuter sur un OS différent, je vous invite à consulter la documentation de Microsoft qui est très bien détaillée à ce propos.
Maintenant, on y va pour le téléchargement. On exécute donc la commande suivante:
wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Elle va simplement télécharger et extraire le fichier dans le répertoire courant sur notre serveur.
Identification du disque à cloner
Nous exécutons la commande lsblk pour lister les disques attachés au serveur. Comme vous pouvez le voir, nous avons deux disques /dev/vdaet /dev/vdb d’une taille respective de 10GB et 466K. Le disque /dev/vdaest le disque système qui contient toutes nos données. Il comprend la partition primaire /dev/vda1 qui est montée à la racine /. C’est ce disque que nous souhaitons imager.

Création de l’image
dd est l’une des commandes les plus importantes de Linux, utilisée principalement pour sauvegarder des disques durs et des partitions. Son emploi va au-delà de la copie au sens strict parce que sa puissance lui permet d’accomplir d’autres tâches un peu « spéciales » mais parfois utile, telles que la: recherche dans les fichiers effacés, recherche dans la mémoire vive, création de disque virtuel etc…
Mais nous, c’est sa capaciter à cloner un disque entier que nous exploiterons.
Avertissement: Avant d’exécuter la commande
ddsuivante, assurez-vous que toutes les applications critiques ont été arrêtées et que votre système est aussi silencieux que possible. La copie d’un disque en cours d’utilisation peut entraîner la corruption de certains fichiers. Veillez donc à arrêter toute opération gourmande en données et à fermer autant d’applications en cours d’exécution que possible.
La commande pour créer notre image, la compresser et la transférer est la suivante:

Oui je sais, ça a l’air complexe mais en réalité ça ne l’est pas. Nous allons décomposer le truc:
dd if=/dev/vda conv=sparse bs=1M- Ici la commande
ddest accompagnée du paramètreifqui correspond à input file, il désigne le disque source à imager. Dans notre cas, c’est le disque/dev/vda. - La commande est également accompagnée de
conv=sparsequi indique à l’utilitaireddd’ignorer l’espace libre et de ne cloner que l’espace disque utilisé. Sans cette option, notre image contiendrait à la fois, les données réelles et l’espace libre présents sur le disque source. - Nous utilisons ensuite
bs=1Mqui correspond à bloc size pour indiquer àddd’effectuer une copie par bloc de 1MB. Ceci permet d’accélérer la copie. La valeur par défaut est de 512 bytes. pv -s 10G- Nous envoyons ensuite la sortie vers l’utilitaire
pvpipe viewer afin de pouvoir suivre visuellement la progression du transfert (ce pipe est optionnel, et nécessite l’installation depvà l’aide de votre gestionnaire de paquets). Sur Ubuntu, il s’installe facilement avec la commandesudo apt install pv -y<br>- Nous utilisons ensuite-s 10Gpuisque la taille du disque initiale est de 10G. Ça nous permet d’obtenir une estimation de la date de fin du transfert. gzip
Puis nous envoyons la sortie versgzippour compresser la taille de l’image afin d’économiser la bande passante lors du transfert vers Azure./azcopy copy 'URL_SAP_modifié' --from-to PipeBlob- Ici, il faut noter l’utilisation de
--from-to PipeBlobqui indique àazcopyque la source à copier provient d’un Pipe.
- L’<em class="markup--em markup--li-em">URL_SAP_modifié</em>représente l’URL SAP générée précédemment dans Azure mais avec un nouvel élément au niveau de l’URI de la ressource de stockage:<strong class="markup--strong markup--li-strong">monimage.img.gz</strong>. Ce dernier est très important et désigne le nom sous lequel apparaîtra notre fichier image au sein de notre conteneur dans Azure.
Je vous passe la commande afin que vous puissiez facilement la copier/coller:
dd if=/dev/vda conv=sparse bs=1M | pv -s 10G | gzip | ./azcopy copy 'https://moncomptedestockage1.blob.core.windows.net/monconteneur/monimage.img.gz?sp=xxxxxxxxxxxxxxxxxxxxx' --from-to PipeBlob
Après exécution, on obtient une sortie similaire dans la console:

Elle indique que la création de notre image et son transfert se sont réalisés en 03 minutes 38 secondes avec un débit de 46.8 MiB/s.
On retourne alors dans Azure pour constater le succès du chargement.
Nous pouvons voir que notre image est bien présente et porte le nom monimage.img.gz. Elle a une taille de 978 MiB contre 10GB pour le disque source.

Conclusion
Dans cet article, nous avons vu comment créer l’image disque d’un serveur Linux et son chargement vers un conteneur de stockage Blob Azure. Cette procédure peut être aussi appliquée lorsque nous souhaitons, migrer un serveur on-premise vers le cloud, passer d’un fournisseur cloud à un autre, ou disposer d’une image de base pour la création d’autres serveurs. Les cas d’usage sont infinis. Dans un prochain article, je vous présenterai comment restaurer un serveur à partir d’une image disque.
Vous pouvez entrer en contact avec moi via les canaux suivants: